
A veces la vida es curiosa. Estoy buscando en una muy torpe base de datos. Tecleo un título, recordando momentos. Sale un resultado. Difícil de creer. Sí, el resultado es un artículo de 2004 relacionado con los complejos de coordinación de la plata con ligandos de tipo tioamida. Sí, el resultado soy yo. ¿Por qué tengo más curiosidad que indignación? La base de datos es pirata. ¿Por qué me genera pensamientos contrapuestos, sintiéndome doblemente utilizado, por una parte por intereses contrapuestos, falsos defensores de los derechos de los científicos (obviando los deberes) y, por la otra, por editoriales que me ponen a mí como víctima académica de una base de datos que lucha contra el sistema? Como cantaba Muguruza, "hay algo aquí que mal ..." Vayamos por partes.

¿Qué es Sci-Hub?
Sci-Hub es un sitio web para buscar artículos científicos. Seguramente es de las más torpes que recuerdo. La diferencia respecto a SCOPUS, ISI Web of Science son "dos detallitos". A Sci-Hub los puedes encontrar en texto completo y son contenidos pirateados. Según dicen, ahora mismo se podrían buscar más de 58 millones de artículos.
Su creadora, Alexandra Elbakyan, nacida en Kazajistán. Cuando piensas en el creador de un sitio ilegal de contenidos, la imagen te lleva a Kim Dotcom, el creador de megaupload, pero aquí hablamos, en cambio, de una joven estudiante que no tenía acceso a todos los artículos que consideraba que necesitaba para su día a día, que tuvo malas experiencias con posibilidades de hacer investigación en el extranjero y que tenía intereses entre las tecnologías de la información y el transhumanismo. Ahora mismo, como publicaba Science (Bohannon, 2016), se dedica a temas de neurociencia y, mientras tanto, gracias a sus conocimientos y contactos, creó la herramienta en 2011 pero fue en 2015 y 2016 cuando se dio a conocer de forma más relevante.
El buscador es muy primitivo, las opciones de búsqueda son una mínima cajita. Evidentemente, está más pensado para localizar un documento ya conocido, que no para buscar un conjunto de artículos o una bibliografía. Se puede buscar por título, URL, DOI o PMID. El primer dominio original fue Sci-Hub.org, que fue cerrado después de la primera demanda de Elsevier y que han ido cayendo contra el servidor. Ahora, alojado en varios dominios espejo, parece que está en Rusia, lo que le permite todavía estar abierta al no tener las mismas dinámicas que si estuviera en Estados Unidos. Es curioso como Rusia está últimamente detrás de las contrainsurgencias informacionales (caso Snowden), por decirlo de alguna forma.
Tal como explica Moya (2016) parece que habrían aprovechado usuarios reales de algunas universidades para descargarse los millones de artículos que parece tener. Muchos de estos son compartidos con LibGen, y cuando no lo encuentran allí (y viceversa) podría aprovechar perfiles de usuarios cedidos por buscar en los fondos de las universidades que están pagando el acceso a las revistas. Las cantidades son ingentes, ahora que hablamos en todo momento de big data. En el juicio celebrado el año pasado, se hablaba de pérdidas de 150.000 $ por artículo. Recordemos, más de 58 millones de artículos a disposición.
¿Quién lo emplea?
Tal como se describe en un buen artículo de Bohannon (2016b), lo primero que hay que saber antes de debatir sobre la utilidad y sobre todo, el significado de todo ello, es conocer los datos de quien lo emplea. En el periodo de septiembre del 2015 a febrero del 2016 se descargaron 28 millones de documentos. De estos, más de 2,6 millones de Irán, 3,4 millones de la India y 4,4 de China (por cierto, el dataset es descargable para poder comprobar los datos).
Podría parecer, sin embargo, que simplemente hablamos de un fenómeno asociado a la fractura entre países desarrollados y los de detrás, pero algo más significa. Miremos la siguiente figura de una mapa interactivo donde los puntos indican desde donde se descargan los artículos.
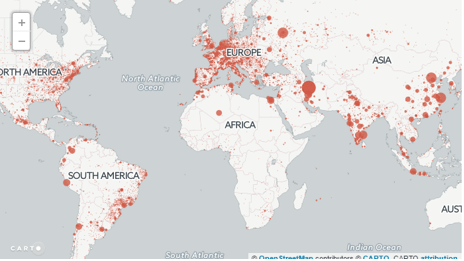
En efecto, miramos el mapa de África y el de Europa. No todo el mundo tiene acceso al "primer mundo" a los artículos científicos. Sí, fuera de las universidades hay un mundo de empresas sin centros de documentación potentes que a menudo pueden necesitar esta herramienta. Y, también, como dice el artículo, estaría pasando que incluso científicos que tienen acceso a los artículos, encuentren más sencillo (un clic) conseguir el artículo de esta forma. ¿Activismo contra las editoriales o vida fácil? difícil de discernir, a día de hoy. Así, los Estados Unidos sería el quinto país en número de artículos descargados. En aquel estudio de seis meses, el artículo más descargado, “Full-scale modal wind turbine tests: comparing shaker excitation with wind excitation”, lo había sido casi 8000 veces.
¿Qué implicaciones presenta para un profesional de la información y para el movimiento Open Access?
¿Por qué no están, pues, los científicos indignados reclamando las pérdidas y exigiendo a las universidades y las editoriales que se respeten sus derechos? ¿Por qué no cuentan los científicos cuanto están dejando de ganar por cada artículo descargado? Pues, porque, paradojas de la vida académica, los científicos han tenido que pagar para que se publiquen aquellos artículos. Sí, con unos modelos de negocio rocambolescos, las editoriales dijeron que si se quería Acceso Abierto a la Ciencia, porque las leyes estatales, las convocatorias europeas y otros lo exigían, esta tenía que ir a cuenta de los proyectos de investigación.
Recuerdo el caso de Napster, el primer servicio P2P que servía, con un servidor central, para poner en contacto a millones de personas que intercambiaban canciones (López y Oppenheim, 2004). En ese caso, grupos como Metallica eran quienes presentaban, junto con las discográficas, las denuncias. También en el caso de megaupload, las denuncias contra Kim Dotcom venían de las productoras. Primero, el sonido, después las películas y las series, ¿y hasta ahora no ha llegado este sacudida al mundo de los pdf? no tiene sentido cuando el retraso en aquel caso iba ligado a las velocidades de descargas que tenían los hogares.
Pero tal y como hicieron todos aquellos casos, hicieron variar el modelo de negocio, Spotify y Netflix son los hijos de segunda generación de modelos de negocio que habían quedado obsoletos. En estos casos, si quien piratea (los científicos) no son los mismos que pagan las facturas (las universidades vía las bibliotecas, en la mayor parte de los casos), esta tensión aún puede durar un tiempo. Pero llegará. Y en ese momento, como en cada caso, los profesionales de la información estaremos en el medio. Y no podremos mirar hacia otro lado. Ciertamente, nos hace sentir extraños. Como no es lo mismo reclamar los derechos sociales que saquear un mercado, los que hace años que luchamos por el Acceso Abierto vemos esta postura extrema. Entre el acceso abierto y la barra libre hay una frontera, y hay que saberla distinguir.
Sí, queremos cambiar el modelo de negocio, pero posiblemente lo que hay que hacer es plantear una alternativa. Sci-hub convierte la brecha que, como en una presa, agrieta el statu quo, pero no es la solución. Mientras tanto, muchos países del países menos desarrollados podrán leer muchos artículos, pero seguirán sin tener suficientes recursos, a menudo para investigar y publicar en esas mismas revistas. Y en las universidades de aquí seguiremos pagando para acceder a muchas revistas que no queremos, a la vez que pagamos por publicar en las que sí queremos. Como diríamos, cornudos y apaleados, pero dos veces.
Para saber más:
Bohannon, J. (2016a). “The frustrated science student behind Sci-Hub”. Science
Bohannon, J. (2016b). “Who's downloading pirated papers? Everyone”. Science
Moya, P. (2016). “Así es cómo una investigadora ha creado la mayor web pirata de artículos científicos”. Omicrono.
López-Borrull, A.; Oppenheim, C. (2004). "Legal aspects of the web". Annual Review of Information Science and Technology. Vol. 38, pp. 483-548
Cita recomendada
LÓPEZ-BORRULL, Alexandre. Sci-Hub o la piratería de artículos científicos: algo sigue sin funcionar. COMeIN [en línea], diciembre 2016, núm. 61. ISSN: 1696-3296. DOI: https://doi.org/10.7238/c.n61.1677

Números anteriores
Comparte
